
WordPressのプラグインActivityPubを使ってWordPressの記事をMastodonで見られるようにしているが、全文だと長いので抜粋する設定を選んでいる。その際に抜粋文字数が極端に短くなることがあって、その対処法は以前に書いた。
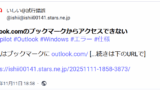
しかし、その対処法でも抜粋された文字数が期待通りの300文字(URLは25文字固定)にはならなかった。その原因の一つは省略記号[...続きは下のURLで]分の文字数(前の半角スペースを含めて15文字)が減らされていたことだった。これに関してはすぐにコードを変えたのだが、それでも抜粋文字数は300文字にならなかった。Geminiに相談しても、難しく考えすぎでコードが複雑になるだけだった。
きっかけは忘れたが、改行文字の文字数が原因ではないかと思いついた。
マストドンなど一般的には改行文字は \n(LF)で1文字とカウントされるが、Windowsでは \r\n(CRLF)で2文字とカウントされることがある。WordPressの記事の入力はWindowsを使っているので、処理されている改行はCRLFの2文字かもしれない。それを1文字に修正すれば、期待通り300文字が抜粋されるのではないかと考えた。
それらを考慮して修正したコードは次のとおりである。テーマファイルエディターの functions.php に記入していたコードを次のように修正した。
// PHPの内部エンコーディングをUTF-8に設定 (文字化け対策)
mb_internal_encoding("UTF-8");
mb_regex_encoding("UTF-8");
// =========================================================================
// 0. FIXED LENGTH AND ASCII EXCERPT MORE DEFINITION
// =========================================================================
// 抜粋長を300文字に固定
define('FIXED_EXCERPT_LENGTH', 300);
// カスタム省略記号(念のためにASCIIのみで確認した後に日本語に)
define('CUSTOM_EXCERPT_MORE_ASCII', ' [...続きは下のURLで]');
// =========================================================================
// 1. URL COMPENSATED TRIM FUNCTION (Multi-byte safe & URL 25文字補正)
// =========================================================================
function custom_mb_trim_url_compensated($string, $length, $excerpt_more) {
$string = str_replace(array("\r\n", "\r"), "\n", $string); // 改行を1文字にする。
$string = preg_replace('/\n{3,}/', "\n\n", $string); // 複数の連なる空白行を一つにする。
if (\mb_strlen($string, 'UTF-8') <= $length) {
return $string;
}
$target_length = $length;
$compensated_content = '';
$current_pos = 0;
$url_pattern = '#(https?:\/\/[\x21-\x7E]+)#iu';
$parts = \preg_split($url_pattern, $string, -1, PREG_SPLIT_DELIM_CAPTURE | PREG_SPLIT_NO_EMPTY);
foreach ($parts as $part) {
if ($current_pos >= $target_length) {
break;
}
if (\preg_match($url_pattern, $part)) {
$compensated_len = 25;
if (($current_pos + $compensated_len) <= $target_length) {
$compensated_content .= $part;
$current_pos += $compensated_len;
} else {
break;
}
} else {
$remaining_count = $target_length - $current_pos;
$text_part = \mb_substr($part, 0, $remaining_count, 'UTF-8');
$compensated_content .= $text_part;
$current_pos += \mb_strlen($text_part, 'UTF-8');
}
}
// マストドンが抜粋の中の<~>をタグと認識したり &~; をエスケープ文字と認識するのを避けるため。
$compensated_content = str_replace('&', '&', $compensated_content);
$compensated_content = str_replace('<', '<', $compensated_content);
$compensated_content = str_replace('>', '>', $compensated_content);
return \trim($compensated_content) . $excerpt_more;
}
// =========================================================================
// 2. THE EXCERPT FILTER (優先度0: 元のコンテンツを取得し、プラグインの処理を迂回)
// =========================================================================
// 優先度0で、ActivityPubプラグインより先に実行されます。
// $post->post_content (記事の生の内容) からタグやエンティティをデコードしたものを返すことで、
// プラグインによる途中の切断を防ぎます。
add_filter('the_excerpt', 'activitypub_get_full_content_for_trimming', 0);
function activitypub_get_full_content_for_trimming($excerpt) {
global $post;
// $postオブジェクトが利用可能な場合
if ($post instanceof WP_Post) {
$full_content = $post->post_content;
} else {
// 利用できない場合は、元の抜粋をそのまま返す
return $excerpt;
}
// ActivityPubプラグインの初期処理を模倣(タグ除去とエンティティデコード)
// これにより、ハッシュタグやウムラウトの問題を回避しつつ、生のコンテンツを取得します。
$content_to_trim = strip_tags($full_content);
$content_to_trim = html_entity_decode($content_to_trim, ENT_QUOTES, 'UTF-8');
// 優先度1のフックに渡す「生のコンテンツ」として返します。
return $content_to_trim;
}
// =========================================================================
// 3. THE EXCERPT FILTER (優先度1: 再トリミングの実行)
// =========================================================================
// 優先度1で、プラグインの処理より後に実行されます。
// 優先度0で受け取った「生のコンテンツ」を、カスタムロジックで再トリミングします。
add_filter('the_excerpt', 'activitypub_fix_mb_excerpt_final', 1);
function activitypub_fix_mb_excerpt_final($excerpt) {
// 抜粋長と省略記号を設定
$length = FIXED_EXCERPT_LENGTH;
$custom_excerpt_more = CUSTOM_EXCERPT_MORE_ASCII;
// $effective_length = $length - \mb_strlen($custom_excerpt_more, 'UTF-8');
$effective_length = $length;
$content_to_trim = \trim($excerpt); // 優先度0で渡された「生のコンテンツ」がここに入ります
// 抜粋が固定値の長さを超えている場合、強制的に再トリミング
if (\mb_strlen($content_to_trim, 'UTF-8') > $effective_length) {
return custom_mb_trim_url_compensated($content_to_trim, $effective_length, $custom_excerpt_more);
}
// 短いコンテンツやトリミング不要な場合は、そのまま返す(ただし、マストドンでの表示に対処する。)
$excerpt = str_replace('&', '&', $excerpt);
$excerpt = str_replace('<', '<', $excerpt);
$excerpt = str_replace('>', '>', $excerpt);
return $excerpt;
}抜粋文に含まれる改行タグがマストドンで改行タグと認識されてしまったり、&~; というエスケープされた文字(例:&)がアンエスケープされて(例:&)しまう問題があったので、それにも対処してコードを修正してある。

この修正コードを使ってからは、抜粋文字数が期待通り300文字(URLは25文字固定)ちょうどになっている。
コメント
custom_mb_trim_url_compensated()関数の「// 複数の連なる空白行を一つにする。」コードの次に、次のコードを追加して、行末の半角スペースを数えないようにした。
$string = preg_replace('/[ \t]+$/m', '', $string); // 行末の半角スペースとタブを削除する。